Publications/Reports
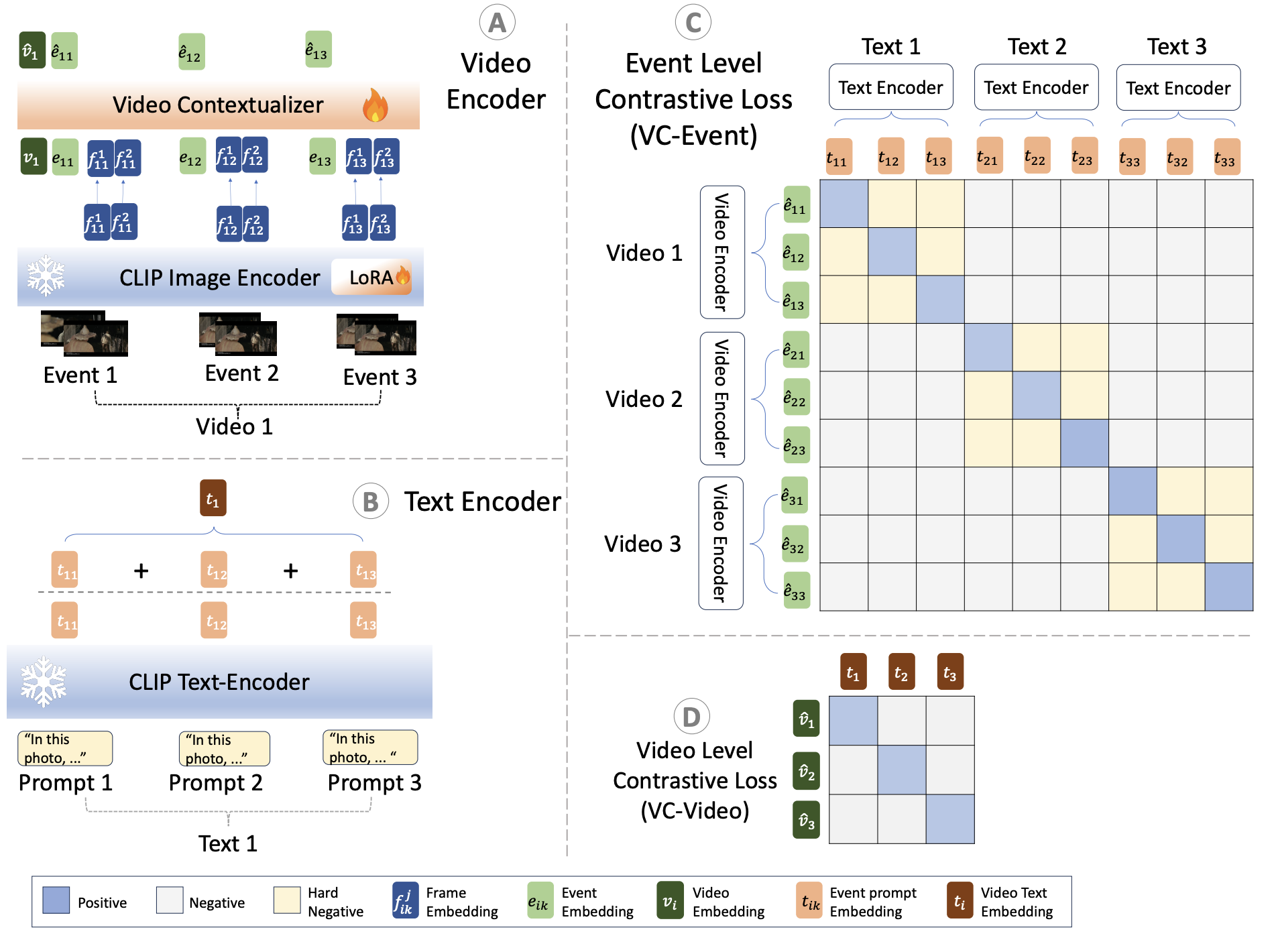
Adapting image-text models like CLIP for video understanding is often inefficient because prior works rely on video datasets with sparse captions that lack the detailed information needed to describe an event holistically. Our paper addresses this by using Semantic Role Labels (SRLs) - a dense, structured format that explicitly captures actions, people, objects, and locations. We demonstrate that simple finetuning on orders of magnitude smaller of such video-caption pairs is adequate to learn powerful, transferable representations applicable across a diverse range of video understanding tasks.
Darshan Singh, Zeeshan Khan, Makarand Tapaswi
CV4Smalls Workshop, CVPR 2026, Best Paper Award 🏆

We introduce CURVE, a challenging benchmark for multicultural and multilingual video reasoning. CURVE comprises high-quality, entirely human-generated annotations from diverse, region-specific cultural videos across 18 global locales in native languages Furthermore, we leverage CURVE’s reasoning traces to construct evidence-based graphs and propose a novel iterative strategy using these graphs to identify fine-grained errors in reasoning. Our evaluations reveal that SoTA Video-LLMs struggle significantly, performing substantially below human-level accuracy, with errors primarily stemming from the visual perception of cultural elements.
Darshan Singh S, Arsha Nagrani, Kawshik Manikantan, Harman Singh,Dinesh Tewari, Tobias Weyand, Cordelia Schmid, Anelia Angelova, Shachi Dave
CVPR 2026, Highlight 🏅

We propose an alternative view of the cross-lingual gap in LLMs, hypothesizing that the variance of responses in the target language (not just differences in latent representations) to be the primary cause behind the drop in performance. We are the first to formalize this gap using bias-variance decomposition, providing extensive experimental evidence to support our hypothesis. Our key finding is that this variance-driven gap can be significantly reduced; we demonstrate that simple inference-time interventions, including a specific prompt instruction to control variance, can improve target language accuracy by 20-25%.
Vihari Piratla, Purvam Jain, Darshan Singh S, Trevor Cohn, Partha Talukdar
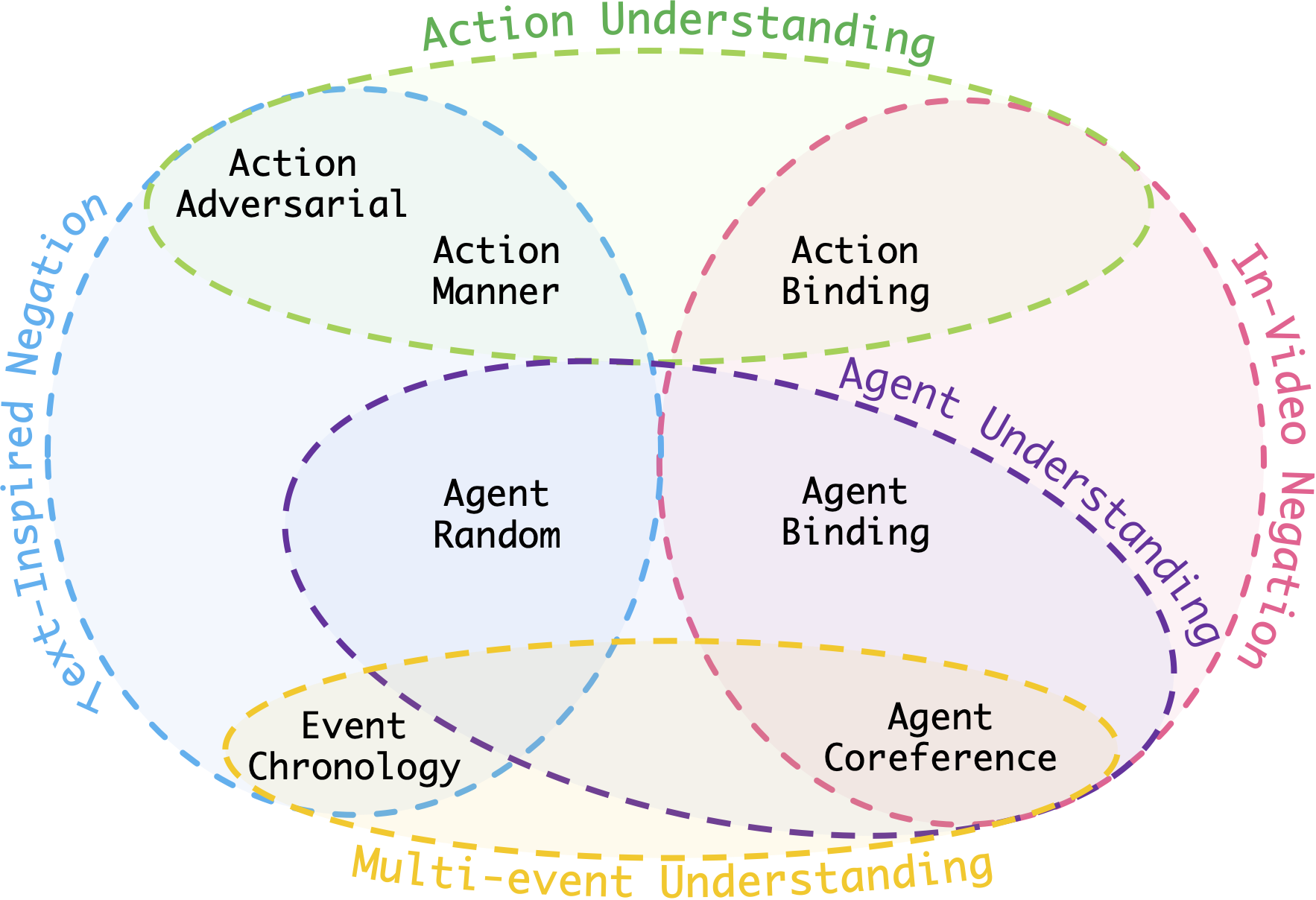
We propose VELOCITI, a new benchmark to evaluate how well Video-LLMs understand compositional reasoning. We introduce StrictVLE (Strict Video-Language Entailment), a new evaluation method that offers a stricter test by requiring models to correctly classify both positive and negative captions. Our key finding is that even state-of-the-art models like Gemini 1.5 Pro (49.3%) perform far below human accuracy (93.0%), showing they significantly struggle to associate agents with their actions, which is one of the most fundamental reasoning skills.
Darshana S*, Varun Gupta*, Darshan Singh S*, Zeeshan Khan, Vineet Gandhi, Makarand Tapaswi
In Conference on Computer Vision and Pattern Recognition (CVPR), 2025

A findings rich paper that systematically improves captioning systems across all fronts- Data, Training, Evaluation. We design- (1) a post-training recipe for self-retrieval finetuning with REINFORCE, and (2) a synthetic framework for visually boosting captioning datasets. Jointly they enable captioners to generate fine-grained, succinct descriptions while reducing hallucinations. Using our training recipe, ClipCap, a 200M param simplication of modern MLLMs, outperforms sota open-source MLLMs on fine-grained visual discrimination.
Manu Gaur, Darshan Singh S, Makarand Tapaswi
Transactions of Machine Learning Research (TMLR), 2024 (J2C Certification, top 10% 🏅)

TL;DR It is easier for MLLMs to select an answer from multiple choices during VQA than to generate it independently. We evaluate MLLMs visual capabilities through self-retrieval within highly similar image pairs, revealing that current models struggle to identify fine-grained visual differences, with open-source models failing to outperform random guess.
Manu Gaur, Darshan Singh S, Makarand Tapaswi
ECCV EVAL-FoMo Workshop, 2024
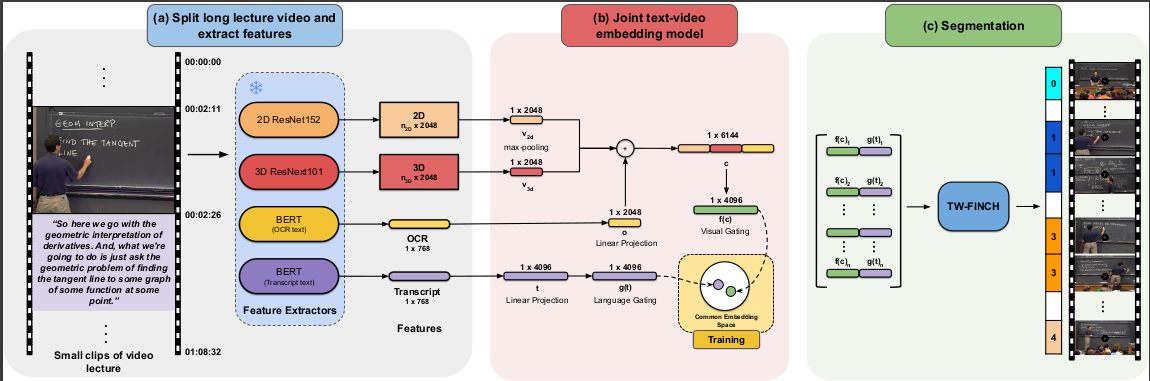
Proposed video lecture segmentation that splits lectures into bite-sized topics. Approached this problem by first learning the lecture-clip representations by leveraging visual, textual, and OCR cues using a pretext self-supervised task of matching lecture narrations with temporally aligned visual content. Used these learned representations to temporally segment the lectures using an algorithm called TW-FINCH. Introduced a new dataset, AVLectures, a large-scale dataset consisting of 86 courses with over 2,350 lectures covering various STEM subjects from MIT-OpenCourseWare, which we used for pre-training, fine-tuning, and evaluating the segmentation performance.
Darshan Singh, Anchit Gupta, C.V. Jawahar and Makarand Tapaswi
Winter Conference on Applications of Computer Vision (WACV), 2023